- 1、安装
- 1.1 Docker
- 1.2 使用 adminer
- 1.3 命令行
- 1.4 idea
- 2、PostgreSQL 语法
- 2.1 创建数据库
- 2.2 创建表
- 2.3 Insert update
- 2.4 常用函数
- 2.5 约束
- 2.6 JOIN UNION AS
- 2.7 不建议用:触发器
- 2.8 索引
- 2.9 自增
- 3、Msql 转 Postgre
- 3.1 数据结构对比
- 3.2 基础语法差异对比
- 3.3 转换
基本用法
参考网址
1、安装
1.1 Docker
使用 docker-compose 脚本进行安装
postgres:image: postgres:15.3-alpine3.18restart: alwaysenvironment:POSTGRES_PASSWORD: exampleports:- 5432:5432volumes:- ${DATA_PATH}/postgres/data:/var/lib/postgresql/data- /etc/localtime:/etc/localtime:roadminer:image: adminerrestart: alwaysports:- 18080:8080
如何提前配置:postgresql.conf
1.2 使用 adminer
- 以下参数必须指定
- 系统:PostgresSQL
- 服务器:postgres
- 用户名:postgres
- 密码:example
- 数据库:不用选

点击登陆,显示你可以操作的数据库
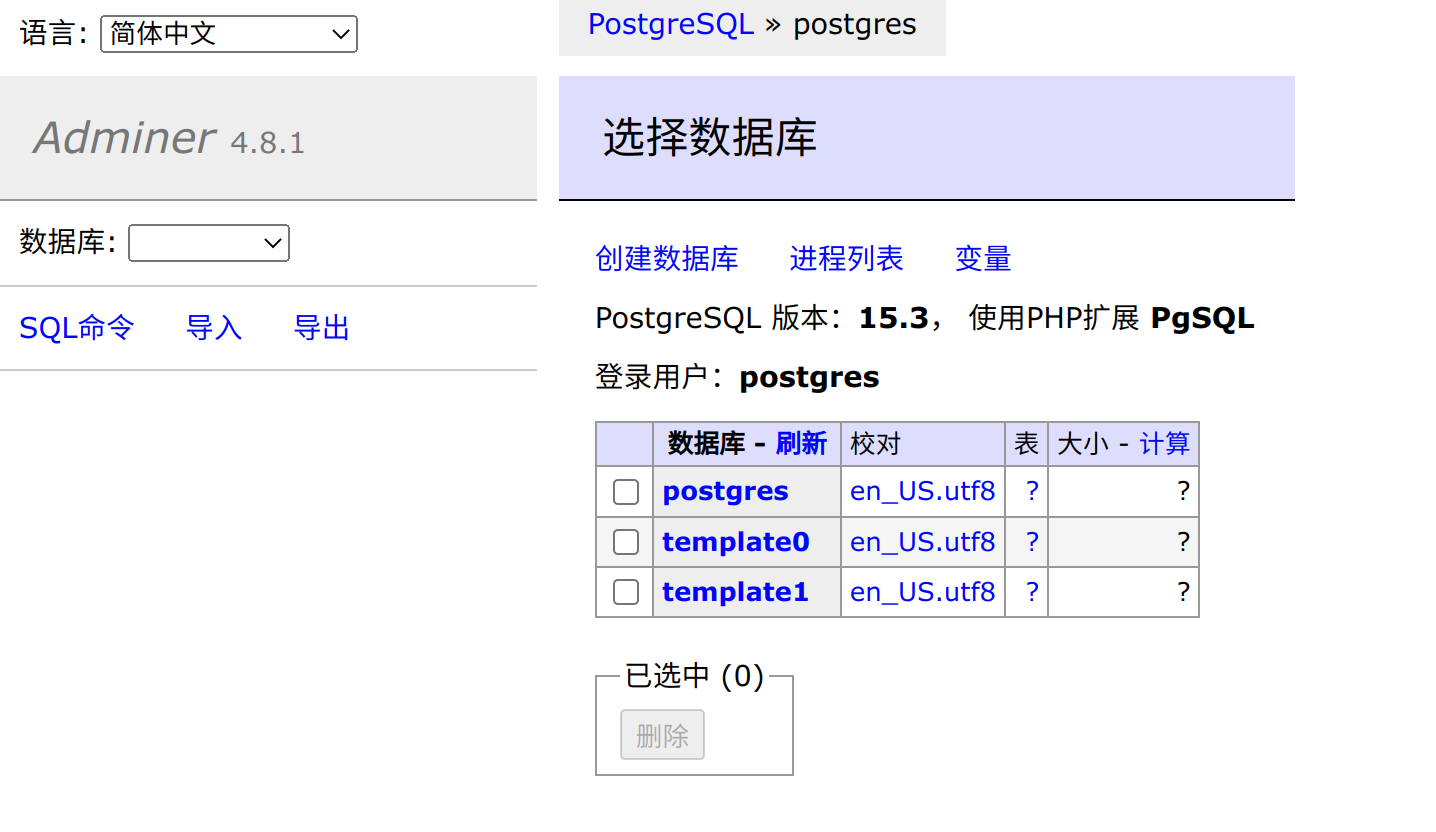
1.3 命令行
# 登录到postgres容器docker-compose exec postgres /bin/bash# 登录到postgres ,为啥不要密码呢?docker-compose exec postgres psql -U postgres
1.4 idea
一定要选择一个 schemas
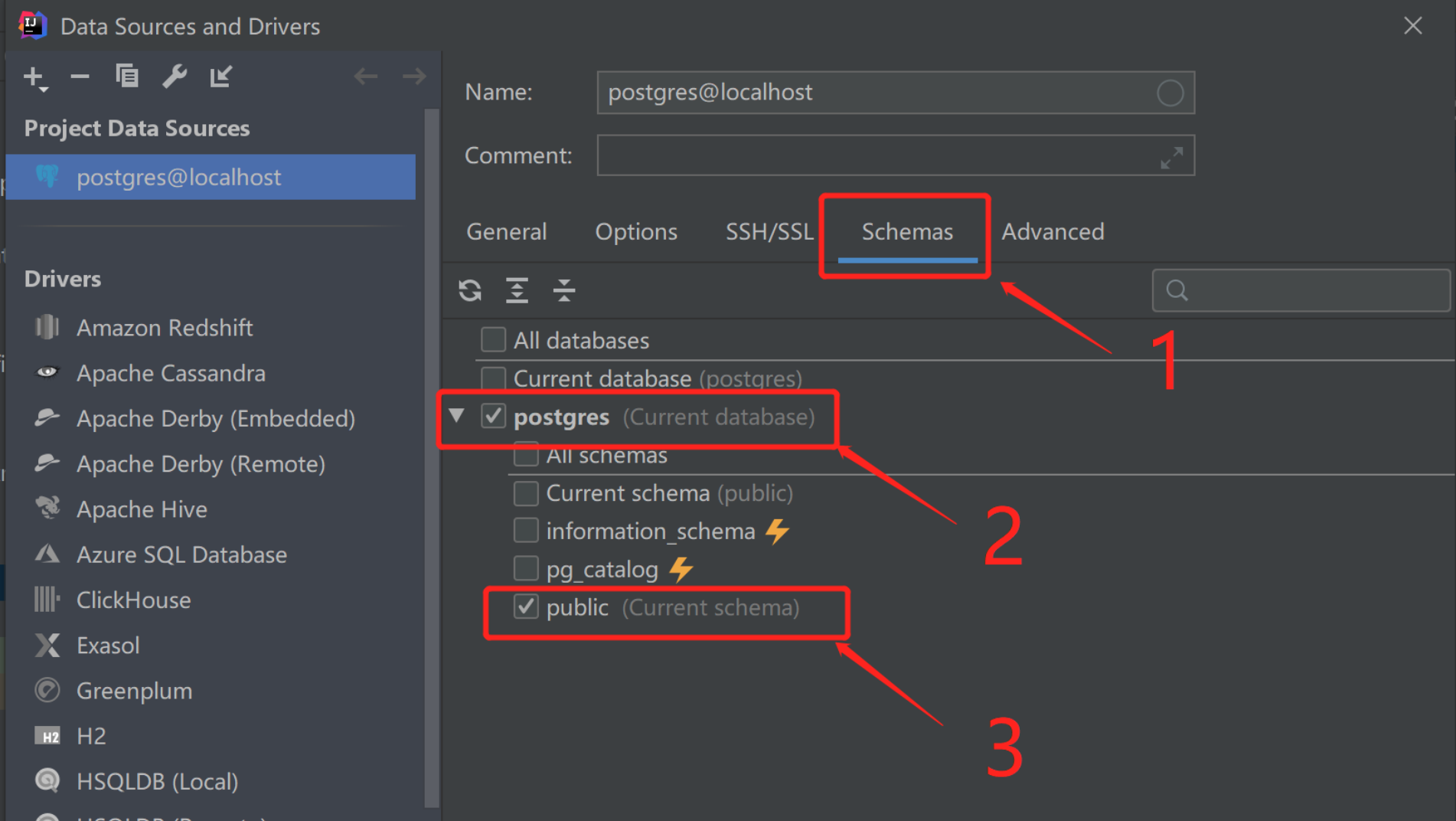
2、PostgreSQL 语法
2.1 创建数据库
# 创建数据库postgres=# create database test;# 进入数据库postgres=# \c test;# 退出当前数据库test=# \c postgres# 删除test数据库postgres=# drop database test;#SELECT 'CREATE DATABASE test1' WHERE NOT EXISTS (SELECT FROM pg_database WHERE datname = 'test1')\gexec
Database VS Schema
下面场景使用 Database
如果你希望对一组数据表的文字编码/排序规则 的默认行为进行定制时,你应该考虑将这组数据表(以及响应的数据库对象)放入一个新建的 Database 中,而不是一个 Schema 中. 这是因为关于文字编码/排序规则等行为的默认规则是以 Database 为单位进行指定的通过
- CREATE DATABASE ${数据库名} WITH ENCODING = ${文字编码名} LC_COLLATE = ${字符串排序顺序};
如果你希望能够对一组数据库表(或 Function 等数据库对象)的并发数进行单独控制时,你应该考虑将这组数据库对象放入一个新建的 Database,而不是一个 Schema 中。因为在 PostgreSQL 中,可以对单个 Database 的最大并发访问的会话数进行单独控制
- CREATE DATABASE ${数据库名} WITH CONNECTION LIMIT = ${最大并发数};
CONNECTION LIMIT 的定义值如果超过了对 postgres 实例定义的
max_connections(定义在 postgresql.conf 中)时则无意义
如果你希望对一组数据库表(或 Function 等数据库对象)的访问进行严格隔离,而不仅仅是通过 SQL 层面的 PRIVILEDGE 来控制。那么你应该考虑将这组数据库对象放入一个新建的 Database,而不是一个 Schema 中。这是因为在 PostgreSQL 中,对于 Access 控制,除了 SQL 级别的权限控制之外,还可以在pg_hba.conf配置文件中进行会话级别的认证控制,基于这种方法,可以对话的以下要素进行高精度的访问控制:
- 会话来源(ip 地址)
- 会话所使用的数据库用户
- 会话的连接目标的 Database 名
由于 Schema 是一个纯逻辑层面的概念,类似于“命名空间”的概念,因此,确实可以按照题主的说法基于不同的 Schema 对业务所需的数据库对象进行 SQL 级别的权限归类。但是,如果数据库设计中对于数据库对象的集合除了基于 SQL 的权限分类外还有诸如以上的特殊需求时,则应当考虑将这些数据库对象定义在一个新的 Database 中。
2.2 创建表
- 如何设置自动增加
- 如何设置字段备注
- Mysql 与 Postgres 数据类型的区别
- 如何添加索引
create table wk_student (student_id BIGINT NOT NULL ,student_name varchar(255) NOT NULL ,student_age int ,student_sex int ,gmt_create timestamp DEFAULT CURRENT_TIMESTAMP NULL ,gmt_modified timestamp DEFAULT CURRENT_TIMESTAMP NULL ,PRIMARY KEY (student_id))
可以创建另外一个表
CREATE TABLE COMPANY(ID INT PRIMARY KEY NOT NULL,NAME TEXT NOT NULL,AGE INT NOT NULL,ADDRESS CHAR(50),SALARY REAL,JOIN_DATE DATE);
查看表
test=# \dList of relationsSchema | Name | Type | Owner--------+------------+-------+----------public | company | table | postgrespublic | wk_student | table | postgres(2 rows)
查看字段
test=# \d wk_studentTable "public.wk_student"Column | Type | Collation | Nullable | Default--------------+-----------------------------+-----------+----------+-------------------student_id | bigint | | not null |student_name | character varying(255) | | not null |student_age | integer | | |student_sex | integer | | |gmt_create | timestamp without time zone | | | CURRENT_TIMESTAMPgmt_modified | timestamp without time zone | | | CURRENT_TIMESTAMPIndexes:"wk_student_pkey" PRIMARY KEY, btree (student_id)
删除表
test=# drop table company;DROP TABLEtest=# \dList of relationsSchema | Name | Type | Owner--------+------------+-------+----------public | wk_student | table | postgres(1 row)
2.3 Insert update
不同的 Insert 写法,与 MaySql 区别不大
test=# INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (1, 'Paul', 32, 'California', 20000.00,'2001-07-13');INSERT 0 1test=# INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (3, 'Teddy', 23, 'Norway', 20000.00, DEFAULT );test=# INSERT INTO COMPANY (ID,NAME,AGE) VALUES (4, 'Jack', 23 );test=# UPDATE COMPANY SET ADDRESS = 'Texas', SALARY=20000;
2.4 常用函数
# 日期表达式返回当前系统的日期和时间SELECT CURRENT_TIMESTAMP;
2.5 约束
- 常用的
- PRIMARY KEY
- UNIQUE
- NOT NULL
- 不建议用的
- FOREIGN KEY 外键约束
- CHECK 约束
- EXCLUDE 约束
CREATE TABLE COMPANY3(ID INT PRIMARY KEY NOT NULL,NAME TEXT NOT NULL,AGE INT NOT NULL UNIQUE,ADDRESS CHAR(50),SALARY REAL DEFAULT 50000.00);
2.6 JOIN UNION AS
- CROSS JOIN :交叉连接。 不要用,笛卡尔积,产生大量数据。
- INNER JOIN:内连接:是最常见的连接类型,是默认的连接类型
- LEFT OUTER JOIN:左外连接 连接的表在 T1 中每一行至少有一行。
- RIGHT OUTER JOIN:右外连接 对于 T2 中的每一行,结果表总是有一行。
- FULL OUTER JOIN:全外连接 对于表 T1 中不满足表 T2 中任何行连接条件的每一行,如果 T2 的列中有 null 值也会添加一个到结果中。
- UNION ALL
- UNION
别名=AS
2.7 不建议用:触发器
2.8 索引
- 组合索引
- 唯一索引
使用索引时,需要考虑下列准则:
- 索引不应该使用在较小的表上。
- 索引不应该使用在有频繁的大批量的更新或插入操作的表上。
- 索引不应该使用在含有大量的 NULL 值的列上。
- 索引不应该使用在频繁操作的列上。
2.9 自增
SMALLSERIAL、SERIAL 和 BIGSERIAL 范围:
| 伪类型 | 存储大小 | 范围 |
|---|---|---|
SMALLSERIAL | 2 字节 | 1 到 32,767 |
SERIAL | 4 字节 | 1 到 2,147,483,647 |
BIGSERIAL | 8 字节 | 1 到 922,337,2036,854,775,807 |
语法如下
CREATE TABLE tablename (colname SERIAL);
3、Msql 转 Postgre
- 一些字段类型
- 自增类型
- 注释
3.1 数据结构对比
| mysql | postgresql |
|---|---|
| TINYINT | SMALLINT |
| SMALLINT | SMALLINT |
| MEDIUMINT | INTEGER |
| BIGINT | BIGINT |
| FLOAT | REAL |
| DOUBLE | DOUBLE PRECISION |
| BOOLEAN | BOOLEAN |
| TINYTEXT | TEXT |
| TEXT | TEXT |
| MEDIUMTEXT | TEXT |
| LONGTEXT | TEXT |
| BINARY(n) | BYTEA |
| VARBINARY(n) | BYTEA |
| TINYBLOB | BYTEA |
| BLOB | BYTEA |
| MEDIUMBLOB | BYTEA |
| LONGBLOB | BYTEA |
| DATE | DATE |
| TIME | TIME [WITHOUT TIME ZONE] |
| DATETIME | TIMESTAMP [WITHOUT TIME ZONE] |
| TIMESTAMP | TIMESTAMP [WITHOUT TIME ZONE] |
| AUTO_INCREMENT | SERIAL , BIGSERIAL |
| column ENUM (value1, value2, […] | column VARCHAR(255) NOT NULL, CHECK (column IN (value1, value2, […])) pg 可以自定义数据类型实现类似效果: CREATE TYPE mood AS ENUM ('sad','ok','happy'); CREATE TABLE person ( current_mood mood ... ) |
3.2 基础语法差异对比
| 语法差异 | mysql | postgresql | 是否相同 |
|---|---|---|---|
| 分页 | select * from t1 limit 2,2; | select * from tbl limit 2 offset 2; | 否 |
| 插入数据时:如果不存在则 insert,存在则 update | replace 实现 | upsert | 否 |
| 大小写兼容 | 通过配置可兼容 | 表字段或表名为大写时,字段或表名必须添加双引号 | 否 |
| if(), case when | if(), case when 条件 1 then 符合值 else 不符合值 end; | case when 条件 1 then 符合值 else 不符合值 end; | 否 |
| round(字段,小数位数) | round(字段,小数位数) | round(case(‘字段’ as numeric),小数位数) | 否 |
| null 值判断 | 支持 ifnull(),NVL(),COALESCE() | 支持 COALESCE() | 否 |
| Update-单表更新 | 相同 | 相同(不可全表更新) | 是 |
| update-更新单表多个字段 | 相同 | 相同 | 是 |
| update-更新并返回 | select tem1,tem2 from update test set tem1 = '',tem2 = '' | UPDATE test SET tem1 = '',tem2 = '' RETURNING tem2,tem2; | 否 |
| Update 表关联更新 | 相同 | 相同 | 是 |
| Insert-单行插入 | 相同 | 相同 | 是 |
| Insert-插入指定字段 | 相同 | 相同 | 是 |
| insert-插入多行 | 相同 | 相同 | 是 |
| insert-插入并返回 | 不支持 | INSERT INTO() RETURNING did | 否 |
| Insert-插入,存在则更新 | INSERT INTO () VALUE() ON DUPLICATE KEY UPDATE name = EXCLUDED.name | INSERT INTO distributors ( did , dname ) VALUES ( 9 , ' Antwerp Design' ) ON CONFLICT (did)DO UPDATE SET name = EXCLUDED.name | 否 |
| insert-不存在插入,存在更新 | replace 实现 | upsert 语句 | 否 |
| SELECT | 相同 | 相同 | 是 |
| DELETE | DELETE FROM table | DELTE FROM table(不可全表删除) | 是 |
| DELETE | DELETE FROM table WHERE | DELETE FROM table WHERE | 是 |
| DELETE-删除并返回 | 不支持 | DELETE FROM table WHERE RETURNING * ; | |
| INDEX-add | 支持 alter,create 创建 | 支持 create | |
| INDEX-delete | 支持 alter,drop | 支持 drop | |
| 字符串常量 | 支持单双引号 | 支持双引号 | 否 |
| 插入数据时自增主键 | 写法一:insert into t1(name) values(‘zhangshan’); 写法二:insert into t1(id, name) values(null, ‘zhangshan’); | insert into t1(name) values(‘zhangshan’); | 否 |
| 库名长度 | 无强制限制 | 库名、表名限制命名长度,建议表名及字段名字符总长度小于等于 63。 |
3.3 转换
- 最简单最常用的工具-navicat premium
- 使用 PGLoader 将 MySQL 数据库迁移到 PostgreSQL
| Mysql | Postgres |
|---|---|
| unsigned | 删除 |
| int | integer |
| DATETIME | timestamp [ (p) ] [ without time zone ] |
| AUTO_INCREMENT | SMALLSERIAL、SERIAL 和 BIGSERIAL 类型 |
UNIQUE KEY wk_student_scores_unique (student_id,course_id) | constraint wk_student_scores_unique unique (student_id,course_id) |
表添加注释 comment on table tb_user is ‘The user table’; 其中 tb_user 替换成对应的表明,单引号内的描述替换为对应表的描述即可。
字段添加注释 comment on column tb_user.id is ‘The user ID’; 其中 tb_user.id 指的是表 tb_user 的 id 字段,同样单引号内的内容为注释的具体信息。