- 1.1 ->
- 1.2 ::
- 1.3 后续
- 2. 函数式接口
- 2.1 核心概念
- 2.2 简介
- 2.3 Function 详解
- 2.4 Consumer
- 2.5 Supplier
- 2.6 UnaryOperator
- 2.7 BiConsumer
- 2.8 BiFunction
- 3. Stream 流开发
- 3.1 简介
- 3.2 创建 Stream
- 3.3 中间操作与终端操作
- 3.4 终端操作
- 3.5 Comparator<T>
- 3.6 终端操作
- 4. Optional
- 4.1 创建
- 4.2 获取
- 4.3 辅助方法
- 参考资料
Lambda 表达式
①②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳✕✓✔✖
在看CAS代码的过程中会遇到很多的 lambda 表达式,需要了解这些写法,才能更好的理解代码。
通过读取这段代码,可以看出 Java 的 Stream 代码写的行云流水,看看起来非常舒服。
1. 表达式
lambda 中->表示匿名函数。::表示引用,理解成一种更简单的箭头函数。
1.1 ->
① 表示形式
Lambda 是一种匿名函数
- 没有名称
- 可以有参数
- 可以有返回值
- 还可能会有异常列表
这里隐含了一个概念匿名类,例如下面类:
@FunctionalInterfacepublic interface Runnable {public abstract void run();}
可以这么来初始化
Runnable r1 = () -> System.out.println("hello lambda");r1.run();
函数式接口定义:接口中只有一个抽象方法的接口,称为函数式接口;可以使用@FunctionalInterface注解修饰,对该接口做检查;如果接口里,有多个抽象方法,使用该注解,会有语法错误
② 自定义
匿名函数这么好? 那么怎么定义一个匿名函数呢?
- 做一个函数接口定义
- 使用现成的函数接口,例如后面讲解的
Cutomer
/*** 自己定义了一个函数式接口*/@FunctionalInterfacepublic interface MyFunction {public abstract Integer run(Integer x ,Integer y,Integer z);}MyFunction c=(x,y,z)->x+y-z;System.out.println(c.run(1,2,3));
今后可以把这个函数做成泛形,就通用性更强了。
1.2 ::
::表示引用,理解成一种更简单的箭头函数。
下面代码为了说明这个例子
@Datapublic class Emp {private String address;private String name;private Integer age;public Emp() {}public Emp(String address) {this.address = address;}public Emp(String name, Integer age) {this.name = name;this.age = age;}public Emp(String address, String name, Integer age) {super();this.address = address;this.name = name;this.age = age;}// 演示如果调用静态方法public static Boolean compareOfStatic(String a,String b){return b.equalsIgnoreCase(a);}// 演示如果调用对象的方法public Boolean compareOfClass(String a){return a.equalsIgnoreCase(this.address);}}
① 方法的引用
有三种形式:
- 类::静态方法名 。 例如
Emp::compareOfStatic - 类::实例方法名 。 例如
Emp::compareOfClass - 对象::实例方法名。 例如
Emp::compareOfClass
/*** 测试类的静态方法引用* 类::静态方法名 = Emp::compareOfStatic*/@Testpublic void testStaticMethod(){BiFunction<String,String,Boolean> biFunction =Emp::compareOfStatic;Boolean ren= biFunction.apply("b","b");System.out.println(ren);}/*** 类::实例方法名=Emp::compareOfClass*/@Testpublic void testClassMethod(){BiFunction<Emp,String,Boolean> biFunction = Emp::compareOfClass;Emp first=new Emp("a","b",1);Boolean ren= biFunction.apply(first,"b");System.out.println(ren);}/*** 对象::实例方法名=Emp::compareOfClass*/@Testpublic void testObjectMethod(){Emp first=new Emp("a","b",1);Function<String,Boolean> fun= first::compareOfClass;Boolean ren= fun.apply("b");System.out.println(ren);}
② 构造函数引用
/*** 演示了用构造函数创建* 1:无参数* 2: 一个参数* 3: 两个参数* 4: 三个参数*/@Testpublic void testStructureFunction(){Supplier<Emp> noArg= Emp::new;System.out.println(noArg.get());Function<String,Emp> oneArg=Emp::new;System.out.println(oneArg.apply("地址"));BiFunction<String,Integer,Emp> towArg=Emp::new;System.out.println(towArg.apply("地址",1));//三个参数,为什么Java不提供三个参数的呢?// 实际上的用法很少会用到三个参数,因为感觉像做递归,fist与next// 如果真要做三个以上参数,可以参考MyFunction来自己定义一个函数接口}
1.3 后续
在上面的例子中用到了这些类的作用是什么?
- BiFunction
- Supplier
- Function
2. 函数式接口
2.1 核心概念
•纯函数
•函数的柯里化
•函数组合
•Point Free
•声明式与命令式代码
•核心概念
Java 最初是面向对象的开发语言,后来往函数方面发展,但是还遗留一些问题。通过读取 Java 的 Lambda 代码,可以了解一下 Java 是如何向函数式编程进行转换。
① 函数变量化
可以使用自定义函数接口或者 JDK 内置的接口,来实现函数的定义。
/*** 自己定义了一个函数式接口*/@FunctionalInterfacepublic interface MyFunction {public abstract Integer run(Integer x ,Integer y,Integer z);}MyFunction c=(x,y,z)->x+y-z;System.out.println(c.run(1,2,3));
但是现在还需要默认的调用c.run()这个方法来执行函数,今后随着 Java 的发展,也会像其他语言一样c()就可以执行了。
② 函数组合
这段代码可以参考Function详解,里面会有详细的说明。
// 演示compose , 这个Function的返回值,是上一个的输入值Function<Emp,Integer> before =(emp)->emp.getName()=="tom"?1:0;Emp testEmp=new Emp("北京","tom1",1);var ren = first.compose(before).apply(testEmp);System.out.println(ren);

③ 柯里化
柯里化:传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数。
// 柯里化之前function add(x, y) {return x + y;}add(1, 2); // 3// 柯里化之后function addX(y) {return function (x) {return x + y;};}addX(2)(1); // 3
事实上柯里化是一种“预加载”函数的方法,通过传递较少的参数,得到一个已经记住了这些参数的新函数,某种意义上讲,这是一种对参数的“缓存”,是一种非常高效的编写函数的方法。
④ Point Free
把一些对象自带的方法转化成纯函数,就不需要命名转瞬即逝的中间变量。
那么 Java 如何实现呢?
⑤ 高阶函数
高阶函数,就是把函数当参数,把传入的函数做一个封装,然后返回这个封装函数,达到更高程度的抽象。
那么 Java 如何实现呢?
⑥ 递归与尾递归
函数调用自身, 称为递归。 如果尾调用自身, 就称为尾递归。 递归需要保存大量的调用记录, 很容易发生栈溢出错误, 如果使用尾递归优化, 将递归变为循环, 那么只需要保存一个调用记录, 这样就不会发生栈溢出错误了。通俗点说,尾递归最后一步需要调用自身,并且之后不能有其他额外操作。
那么 Java 如何实现呢?
2.2 简介
函数式接口的定义:接口中只有一个抽象方法的接口,称为函数式接口;
可以使用@FunctionalInterface注解修饰,对该接口做检查;如果接口里,有多个抽象方法,使用该注解,会有语法错误。本节内容参考了
① 5 个核心接口
- Runnable
- 无参无返回值
- Consumer
- 有一个参数,无返回值的
- Supplier
- 无参数、有返回值
- Function<T,R>
- 一个参数,多个返回值
- Predicate
- 断言接口
② 扩展接口
UnaryOperator- 一元运算符,继承了 Function,Function 可以接收两个不同类型的变量
- 但是
UnaryOperator只接收一个泛型参数 T,并返回 T
BiConsumer<T, U>- 相对 consumer,有两个参数
③ JDK1.8前有的
java.lang.Runnablejava.util.concurrent.Callablejava.security.PrivilegedActionjava.util.Comparatorjava.io.FileFilterjava.nio.file.PathMatcherjava.lang.reflect.InvocationHandlerjava.beans.PropertyChangeListenerjava.awt.event.ActionListenerjavax.swing.event.ChangeListener
④ java.util.function中内置的
- 术语
Bi或者Binary都表示二元操作。unary表示一元操作and、negate、or:判断运算符:并且、与、或者
- 操作类型
| 名称 | 参数 | 返回 | 方法 |
|---|---|---|---|
| Consumer | 0-1 | ✖ | void accept(T t);Default 方法: andThen |
| Supplier | ✖ | ✔ | T get(); |
| Function<T, R> | 1-2 | ✔ | R apply(T t);Default 方法: compose、andThen、identity |
| operator | 1-2 | ✔ | 同Function |
| Predicate | 1-2 | Boolean | boolean test(T t)Default 方法: and、negate、or、isEqual、not |
在函数名称前如果有下面的前缀
- Bi 或 Binary 表示 2 个参数。默认是一个参数
- 类型符号,例如:Int、Double 等,表示参数类型
下面列出一些常用的函数接口
| 名称 | 参数 | 返回 | 主函数 | 说明 |
|---|---|---|---|---|
| BiConsumer<T,U> | 2 | ✖ | accept | Default 方法:andThen |
| BiFunction<T,U,R> | 2 | R | apply | Default 方法:andThen |
| BinaryOperator | 2 | T | apply | 参与与返回值的类型都是 T 继承了 BiFunction<T,T,T>,并且增加了两个函数:得到最小值,得到最大值Default 方法: minBy、maxBy |
| BiPredicate<T,U> | 2 | Boolean | test | 返回 Boolean Default 方法: and、negate、or |
| BooleanSupplier | ✖ | Boolean | getAsBoolean | 返回 Boolean |
| Consumer | 1 | ✖ | accept | Default 方法:andThen |
| DoubleBinaryOperator | 2 | Double | applyAsDouble | 返回 Double,两个参数是 Double |
| DoubleConsumer | 1 | ✖ | accept | 参数是 Double Default 方法: andThen |
| DoubleFunction | 1 | R | apply | 参数是 Double,返回是 R |
| DoublePredicate | 1 | Boolean | test | 参数是 Double,返回是 Boolean Default 方法: and、negate、or |
| DoubleSupplier | ✖ | Double | getAsDouble | 返回 Double |
| DoubleToIntFunction | 1 | Int | applyAsInt | 输入 Double 返回 Int |
| DoubleToLongFunction | 1 | Long | applyAsLong | 输入 Double 返回 Long |
| DoubleUnaryOperator | 1 | Double | applyAsDouble | 输入一个参数,返回一个参数,都是 Double Default 方法: compose、andThen、identity |
| Function<T,R> | 1 | R | apply | Default 方法:compose、andThen、identity |
| IntBinaryOperator | 2 | Int | applyAsInt | 输入两个参数,返回一个参数,都是 Int |
| IntConsumer | 1 | ✖ | accept | Default 方法:andThen |
| IntFunction | 1 | R | apply | |
| IntPredicate | 1 | Boolean | test | Default 方法:and、negate、or |
| IntSupplier | ✖ | int | getAsInt | |
| IntToDoubleFunction | 1 | Double | applyAsDouble | |
| IntToLongFunction | 1 | Long | applyAsLong | |
| IntUnaryOperator | 1 | int | applyAsInt | 输入输出都是 int Default 方法: compose、andThen、identity |
| LongBinaryOperator | 2 | long | ||
| LongConsumer | 1 | ✖ | ||
| LongFunction | 1 | long | ||
| LongPredicate | 1 | Boolean | ||
| LongSupplier | ✖ | long | ||
| LongToDoubleFunction | 1 | Double | ||
| LongToIntFunction | 1 | Int | ||
| LongUnaryOperator | 1 | Long | ||
| ObjDoubleConsumer | 2 | T | ||
| ObjIntConsumer | 2 | ✖ | ||
| ObjLongConsumer | 2 | ✖ | ||
| Predicate | 1 | Boolean | ||
| Supplier | 1 | ✖ | ||
| ToDoubleBiFunction | 2 | Double | ||
| ToDoubleFunction | 1 | Double | ||
| ToIntBiFunction | 2 | Int | ||
| ToIntFunction | 1 | Int | ||
| ToLongBiFunction | 2 | Long | ||
| ToLongFunction | 1 | Long | ||
| UnaryOperator | 1 | T |
2.3 Function 详解
@FunctionalInterfacepublic interface Function<T, R> {R apply(T t);default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {Objects.requireNonNull(before);return (V v) -> apply(before.apply(v));}default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {Objects.requireNonNull(after);return (T t) -> after.apply(apply(t));}static <T> Function<T, T> identity() {return t -> t;}}
① 代码分析
public interface Function<T, R> {
输入 T,返回 R
R apply(T t);
apply 是具体实现的函数,输入 T,返回 R。
default <V> Function<V, R> compose(Function<? super V, ? extends T> before)
compose 实现了函数转换,返回一个函数,实现了输入 V,返回 R 的转换。
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after)
将最初的输入 T 输出 R,变成输入 T 输出 V,在中间加入了一个新的函数。
static <T> Function<T, T> identity()
返回一个函数,这个函数是输入什么,就返回什么。为什么要这个函数,因为有些情况下的参数是一个函数,但是这个函数没有对具体的数据进行什么加工。可以看这篇文档
② 例子代码
看下面的例子,就清楚了。
// 演示FunctionFunction<Integer,String> first=(id)->id>0?"true":"false";System.out.println(first.apply(1));// 演示compose , 这个Function的返回值,是上一个的输入值Function<Emp,Integer> before =(emp)->emp.getName()=="tom"?1:0;Emp testEmp=new Emp("北京","tom1",1);var ren = first.compose(before).apply(testEmp);System.out.println(ren);// 演示andThenFunction<String,Boolean> after=str->str.equalsIgnoreCase("true")?true:false;Boolean afterRen= first.andThen(after).apply(1);System.out.println(afterRen);// 演示identityFunction<Integer,Integer> inden= Function.identity();Integer ren2= inden.apply(1);System.out.println(ren2);
③ 衍生函数
下面我们看下 Funtion 这个接口的“扩展”的原始类型特化的一些函数接口
IntFunction<R>,IntToDoubleFunction,IntToLongFunction,LongFunction<R>,LongToDoubleFunction,LongToIntFunction,DoubleFunction<R>,ToIntFunction<T>,ToDoubleFunction<T>,ToLongFunction<T>
我们在做基础数据处理的时候(eg: Integer i=0; Integer dd= i+1;),会对基础类型的包装类,进行拆箱的操作,转成基本类型,再做运算处理,拆箱和装箱,其实是非常消耗性能的,尤其是在大量数据运算的时候;这些特殊的 Function 函数式接口,根据不同的类型,避免了拆箱和装箱的操作,从而提高程序的运行效率。
④ 泛型知识
只用知道 extends 为了取东西,super 为了存东西。下面可以不看
- 是指 “**上界通配符(Upper Bounds Wildcards)**”
- 是指 “**下界通配符(Lower Bounds Wildcards)**”
最后看一下什么是PECS(Producer Extends Consumer Super)原则,已经很好理解了:
- 上界<? extends T>不能往里存,只能往外取
- 因为不知道?号里面具体保存的是啥内容
- 下界<? super T>不影响往里存,但往外取只能放在 Object 对象里
- 频繁往外读取内容的,适合用上界 Extends。
- 经常往里插入的,适合用下界 Super。
为什么要用通配符和边界?
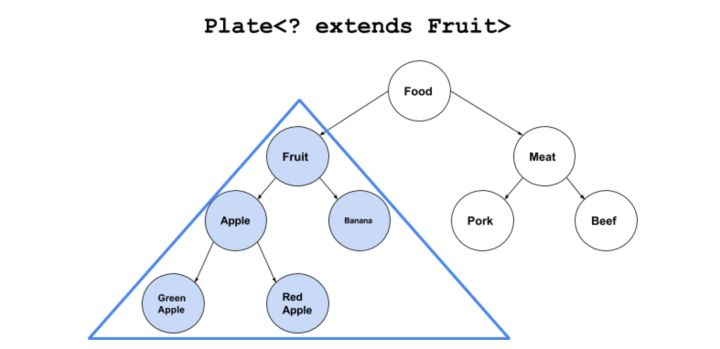
上界通配符
// 啥水果都能放的盘子 如果没有 extends 就会报错Plate<? extends Fruit> p=new Plate<Apple>(new Apple());
这样就可以使用上边界,来保存所有的水果了。
下界通配符
Plate<? super Fruit>
只要是祖先类是Fruit,都可以使用。
2.4 Consumer
相对于Funciton就是一个没有返回值的函数。
源代码
public interface Consumer<T> {void accept(T t);default Consumer<T> andThen(Consumer<? super T> after) {Objects.requireNonNull(after);return (T t) -> { accept(t); after.accept(t); };}}
直接看例子吧
Consumer<Integer> consumer=x->{System.out.println(x+1);};consumer.accept(1);Consumer<Integer> after= x->{System.out.println("后期处理函数:"+x);};consumer.andThen(after).accept(1);
输出的内容如下:
22后期处理函数:1
2.5 Supplier
@FunctionalInterfacepublic interface Supplier<T> {T get();}
看语义,可以看到,这个接口是一个提供者的意思,只有一个 get 的抽象类,没有默认的方法以及静态的方法,传入一个泛型 T 的,get 方法,返回一个泛型 T
2.6 UnaryOperator
@FunctionalInterfacepublic interface UnaryOperator<T> extends Function<T, T> {static <T> UnaryOperator<T> identity() {return t -> t;}}
这个接口继承 Function 接口,Funtion 接口,定义了一个 apply 的抽象类,接收一个泛型 T 对象,并且返回泛型 T 对象。
UnaryOperator<Integer> dda = x -> x + 1;System.out.println(dda.apply(10));// 11UnaryOperator<String> ddb = x -> x + 1;System.out.println(ddb.apply("aa"));// aa1
2.7 BiConsumer
@FunctionalInterfacepublic interface BiConsumer<T, U> {void accept(T t, U u);default BiConsumer<T, U> andThen(BiConsumer<? super T, ? super U> after) {Objects.requireNonNull(after);return (l, r) -> {accept(l, r);after.accept(l, r);};}}
例子
BiConsumer<Integer,String> biConsumer = (k,v)->{System.out.println("key:"+k);System.out.println("value:"+v);};biConsumer.accept(1,"beijing");
Map 接口的终端操作,forEach 的参数就是 BiConsumer 函数接口,对 HashMap 的数据进行消费;BiConsumer 函数接口还有一个默认函数,andThen,接收一个 BiConsumer 接口,先执行本接口的,再执行传入的参数。
Map<String, String> map = new HashMap<>();map.put("a", "a");map.put("b", "b");map.put("c", "c");map.put("d", "d");map.forEach((k, v) -> {System.out.println(k);System.out.println(v);});
2.8 BiFunction
这个就意思了,只有andThen
@FunctionalInterfacepublic interface BiFunction<T, U, R> {R apply(T t, U u);default <V> BiFunction<T, U, V> andThen(Function<? super R, ? extends V> after) {Objects.requireNonNull(after);return (T t, U u) -> after.apply(apply(t, u));}}
例子
BiFunction<Integer,Integer,Integer> add =(x,y)->x+y;Integer ren = add.apply(1,2);System.out.println(ren);Function<Integer,Integer> mod=(x)->x-1;Integer ren2=add.andThen(mod).apply(1,2);System.out.println(ren2);// (1+2)-1
要是有一个 compose,就好了
3. Stream 流开发
3.1 简介
Java 8 API 添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API 可以极大提高 Java 程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
+--------------------+ +------+ +------+ +---+ +-------+| stream of elements +-----> |filter+-> |sorted+-> |map+-> |collect|+--------------------+ +------+ +------+ +---+ +-------+
以上的流程转换为 Java 代码为:
List<Integer> transactionsIds =widgets.stream().filter(b -> b.getColor() == RED).sorted((x,y) -> x.getWeight() - y.getWeight()).mapToInt(Widget::getWeight).sum();
什么是 Stream?
Stream(流)是一个来自数据源的元素队列并支持聚合操作
- 元素是特定类型的对象,形成一个队列。 Java 中的 Stream 并不会存储元素,而是按需计算。
- 数据源 流的来源。 可以是集合,数组,I/O channel, 产生器 generator 等。
- 聚合操作 类似 SQL 语句一样的操作, 比如 filter, map, reduce, find, match, sorted 等。
和以前的 Collection 操作不同, Stream 操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过 Iterator 或者 For-Each 的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream 提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
生成流
在 Java 8 中, 集合接口有两个方法来生成流:
- stream() − 为集合创建串行流。
- parallelStream() − 为集合创建并行流。
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");List<String> filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList());
并行(parallel)程序
parallelStream 是流并行处理程序的代替方法。以下实例我们使用 parallelStream 来输出空字符串的数量:
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");// 获取空字符串的数量long count = strings.parallelStream().filter(string -> string.isEmpty()).count();
我们可以很容易的在顺序运行和并行直接切换。
Collectors
Steame中collet的定义
// supplier处理器 accumulator累加器 combiner组合器<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner);<R, A> R collect(Collector<? super T, A, R> collector);
Collector类源代码
// A 结果类型,T 中间操作类型,R 最终返回类型,一般情况下,A=Rpublic interface Collector<T, A, R> {public static<T, R> Collector<T, R, R> of(// 源数据对象类型(中间操作对象类型)Supplier<R> supplier,// T 中间操作类型BiConsumer<R, T> accumulator,//并发 合并部分结果BinaryOperator<R> combiner,// 当前收集器的特性Characteristics... characteristics) {Objects.requireNonNull(supplier);Objects.requireNonNull(accumulator);Objects.requireNonNull(combiner);Objects.requireNonNull(characteristics);Set<Characteristics> cs = (characteristics.length == 0)? Collectors.CH_ID: Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH,characteristics));return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, cs);}public static<T, A, R> Collector<T, A, R> of(Supplier<A> supplier,BiConsumer<A, T> accumulator,BinaryOperator<A> combiner,// 可选,对结果集的转换Function<A, R> finisher,Characteristics... characteristics) {Objects.requireNonNull(supplier);Objects.requireNonNull(accumulator);Objects.requireNonNull(combiner);Objects.requireNonNull(finisher);Objects.requireNonNull(characteristics);Set<Characteristics> cs = Collectors.CH_NOID;if (characteristics.length > 0) {cs = EnumSet.noneOf(Characteristics.class);Collections.addAll(cs, characteristics);cs = Collections.unmodifiableSet(cs);}return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, finisher, cs);}.................................}
Collectors 类实现了很多归约操作,例如将流转换成集合和聚合元素。Collectors 可用于返回列表或字符串:
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");List<String> filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList());System.out.println("筛选列表: " + filtered);String mergedString = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.joining(", "));System.out.println("合并字符串: " + mergedString);
统计类
例如IntSummaryStatistics等,一些产生统计结果的收集器也非常有用。它们主要用于 int、double、long 等基本类型上,它们可以用来产生类似如下的统计结果。
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);IntSummaryStatistics stats = numbers.stream().mapToInt((x) -> x).summaryStatistics(); System.out.println("列表中最大的数 : " + stats.getMax());System.out.println("列表中最小的数 : " + stats.getMin());System.out.println("所有数之和 : " + stats.getSum());System.out.println("平均数 : " + stats.getAverage());Random random = new Random();random.ints().limit(10).forEach(System.out::println);
3.2 创建 Stream
3.2.1 Stream 静态方法
① Stream.of
例子
String[] dd = { "a", "b", "c" };Stream.of(dd).forEach(System.out::print);// abc
源代码
@SafeVarargs@SuppressWarnings("varargs") // Creating a stream from an array is safepublic static<T> Stream<T> of(T... values) {return Arrays.stream(values);}
在声明具有模糊类型(比如:泛型)的可变参数的构造函数或方法时,Java 编译器会报 unchecked 警告。可使用@SafeVarargs 进行标记,这样的话,Java 编译器就不会报 unchecked 警告。
② Stream.iterate
Stream.iterate(0, x -> x + 1).limit(10).forEach(System.out::print);// 0123456789
Stream.iterate,是 Stream 接口下的一个静态方法,是以迭代器的形式,创建一个数据流,具体的静态方法定义如下:
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f) {Objects.requireNonNull(f);final Iterator<T> iterator = new Iterator<T>() {@SuppressWarnings("unchecked")T t = (T) Streams.NONE;@Overridepublic boolean hasNext() {return true;}@Overridepublic T next() {return t = (t == Streams.NONE) ? seed : f.apply(t);}};return StreamSupport.stream(Spliterators.spliteratorUnknownSize(iterator,Spliterator.ORDERED | Spliterator.IMMUTABLE), false);}
,传入两个参数,一个泛型 T 对象,表示数据的起始,一个函数式接口 UnaryOperator,从迭代器 hasNext 中,可以看到,返回一直为 true,表示迭代器,会一直执行下去,创建的数据集合的值为泛型 T 对象;这样一直创建无限个对象的流,也成为无限流;
③ Stream.generate
Stream.generate(() -> "x").limit(10).forEach(System.out::print);// xxxxxxxxxx
Stream.generate,也是 stream 中的一个静态方法,静态方法定义如下:
public static<T> Stream<T> generate(Supplier<T> s) {Objects.requireNonNull(s);return StreamSupport.stream(new StreamSpliterators.InfiniteSupplyingSpliterator.OfRef<>(Long.MAX_VALUE, s), false);}
传入一个函数式接口 Supplier,这个静态方法,也是无限生成对象的集合流,也是一个无限流;
3.2.2 集合自带方法
① Arrays.stream
String[] dd = { "a", "b", "c" };Arrays.stream(dd).forEach(System.out::print);// abc
② Collection.stream
如:Set,List,Map,SortedSet 等等
String[] dd = { "a", "b", "c" };List list=Arrays.asList(dd);list.stream().forEach(System.out::print);// abc
3.3 中间操作与终端操作
public interface Stream<T> extends BaseStream<T, Stream<T>> {Stream<T> filter(Predicate<? super T> predicate);Stream<T> distinct();Stream<T> sorted();Stream<T> sorted(Comparator<? super T> comparator);Stream<T> peek(Consumer<? super T> action);Stream<T> limit(long maxSize);Stream<T> skip(long n);<R> Stream<R> map(Function<? super T, ? extends R> mapper);//下面是终端操作void forEach(Consumer<? super T> action);Optional<T> min(Comparator<? super T> comparator);long count();.........................................................}
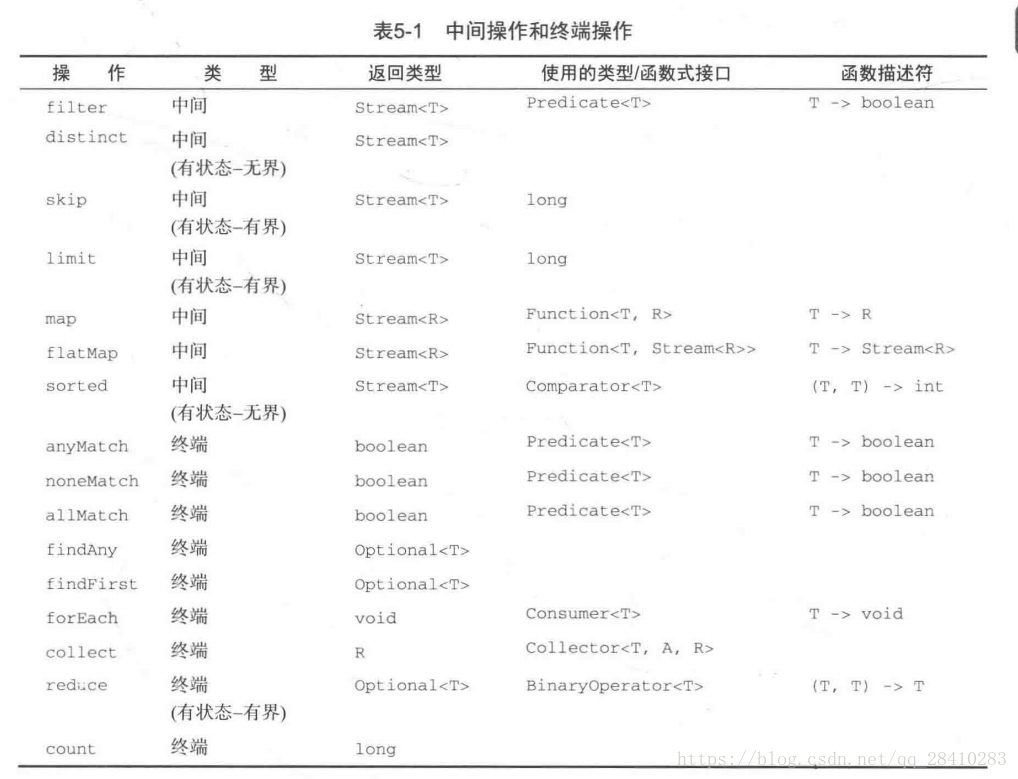
查看 Stream 源代码,发现返回值有两类:
- Stream
:这些函数称作中间操作 - 其他类型:这些函数称作终端操作
3.4 终端操作
3.4.1 map、filter、flatMap
① filter
Stream<T> filter(Predicate<? super T> predicate);
filter 方法用于通过设置的条件过滤出元素。以下代码片段使用 filter 方法过滤出空字符串:
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");// 获取空字符串的数量long count = strings.stream().filter(string -> string.isEmpty()).count();
② map
源代码,输入一个参数,返回一个参数
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
map 方法用于映射每个元素到对应的结果,以下代码片段使用 map 输出了元素对应的平方数:
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);// 获取对应的平方数List<Integer> squaresList = numbers.stream().map( i -> i*i).distinct() //去重.collect(Collectors.toList());
③ flatMap
接口定义
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
Function 定义:
- T
- 返回流
返回:
Stream<R>
public static void main(String[] args) {List<String> list = Arrays.asList("a1","a2","a3");//一对一的处理,在每个字符串后面加上test输出list.stream().map(s->s+"test").forEach(System.out::println);////一对多的处理,把每个字符串拆成一个个字符,输出,这点map就无法做到。list.stream().flatMap(s -> Stream.of(s.split(""))).forEach(System.out::println);}
flatMap,输入一个变量,但是返回的是一个流。
案例:对给定单词列表 ["Hello","World"],你想返回列表["H","e","l","o","W","r","d"],应该怎么做? 这里有怎么做的不同方法,但是文章写的又掉绕,按照自己的想法,写一个具体的内容吧。
@Testpublic void FlatMapTest(){String[] words = new String[]{"Hello","World"};//直接输出,没有做任何处理Stream.of(words).forEach(System.out::println);//map 将一个流中的每个元素做了处理,然后输出相同数量的流内容Stream.of(words).map(s->s.length()).forEach(System.out::println);//flat实际上,将一个stream转换成两外一个streamStream.of(words).flatMap(s->Stream.of(s.split(""))).forEach(System.out::println);//去重复,输出HeloWrdString ren=Stream.of(words).flatMap(s->Stream.of(s.split(""))).distinct().collect(Collectors.joining());System.out.println(ren);}
3.4.2 distinct,sorted,peek,limit,skip
//去重复Stream<T> distinct();//排序Stream<T> sorted();//根据属性排序Stream<T> sorted(Comparator<? super T> comparator);//当前元素进行操作Stream<T> peek(Consumer<? super T> action);//截断--取先maxSize个对象Stream<T> limit(long maxSize);//截断--忽略前N个对象Stream<T> skip(long n);
①②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳
① distinct
//去重排序Stream.of(2,1,2,3).distinct().sorted().forEach(System.out::println);
② sorted
有两个用法:
- sorted()
- sorted(Comparator<? super T> comparator);
这里重点对Comparator说明一下。请看下一节,有重点说明
- 升序降序
- 再次排序
- 自定义排序
- 等等
③ peek
看例子,感觉用 Map 麻烦的话,可以用 Peek
//给大于30岁的人,加薪300元System.out.println("--------------------------------");empList.stream().filter(emp->emp.getAge()>30).map(emp->{emp.setSalary(emp.getSalary()+300);return emp;}).forEach(System.out::println);//用peek来处理System.out.println("--------------------------------");empList.stream().filter(emp->emp.getAge()>30).peek(emp->emp.setSalary(emp.getSalary()+300)).forEach(System.out::println);
peek 源码的定义,需要传入一个Consumer
Stream<T> peek(Consumer<? super T> action);
④ skip&limit
感觉像分页的应用,看例子代码
//按照年龄排序,跳过前两个,只取2个System.out.println("--------------------------------");empList.stream().sorted(Comparator.comparing(Emp::getAge)).skip(2).limit(2).forEach(System.out::println);System.out.println("--------------------------------");// 数字从1开始迭代(无限流),下一个数字,是上个数字+1,忽略前5个 ,并且只取10个数字Stream.iterate(1, x -> ++x).skip(5).limit(10).forEach(System.out::println);
3.5 Comparator<T>
这个类对排序非常重要,所以单独列出了一个章节来说。
3.5.1 默认方法
@FunctionalInterfacepublic interface Comparator<T> {int compare(T o1, T o2);....还有好多静态方法}
这个类是一个函数式接口。可以进行简化处理,例如下面的代码
//倒序Stream.of(2,1,2,3).distinct().sorted((o1,o2)->{return o2-o1;}).forEach(System.out::println);
其中(o1,o2) 这部分就是一个接口式函数的实现。
但是上面自己写方法很麻烦,实际上Comparator内置了很多有用的方法。
3.5.2 comparing 方法
① 最简单用法
下面是一个简单的例子,使用了 Key 默认的比较器。
//按照名称排序empList.stream().sorted(Comparator.comparing(Emp::getAge)).forEach(emp->System.out.println(emp));
这个例子中comparing接受一个函数,这个函数可以返回一个数值。那么看看 comparing 的源代码
/**传入一个Function类型的参数,keyExtractor。Extractor表示提取器,这个函数用来提取一个数值,由于是接口函数,所以通过apply(c1)来提取。keyExtractor.apply(c1)=Emp::getAge =emp.getAge()*/public static <T, U extends Comparable<? super U>> Comparator<T> comparing(Function<? super T, ? extends U> keyExtractor){Objects.requireNonNull(keyExtractor);return (Comparator<T> & Serializable)(c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2));}
② 自定义比较器
认为自身的比较器不好用的时候,可以把第二个参数,作为比较器传入,具体看下面的例子。
empList.stream().sorted(Comparator.comparing(Emp::getAge,(a,b)->b-a)).forEach(emp->System.out.println(emp));
上面例子中(a,b)->b-a)就是作为第二个参数传入的。那么看看源代码长的是啥样子。
public static <T, U> Comparator<T> comparing(Function<? super T, ? extends U> keyExtractor,Comparator<? super U> keyComparator){Objects.requireNonNull(keyExtractor);Objects.requireNonNull(keyComparator);return (Comparator<T> & Serializable)(c1, c2) -> keyComparator.compare(keyExtractor.apply(c1),keyExtractor.apply(c2));}
这里多了一个参数keyComparator,翻译一下就是 key 的比较器。当然如果自己写比较器,太麻烦了,Java 内置了一些比较器。
③ 特定比较器
还有三个比较器,分别使用了Double.compare、Long.compare、Integer.compare。这样做为了提高效率,但是要把内容转换成对应的类型。
public static <T> Comparator<T> comparingInt(ToIntFunction<? super T> keyExtractor)public static <T> Comparator<T> comparingLong(ToLongFunction<? super T> keyExtractor)public static<T> Comparator<T> comparingDouble(ToDoubleFunction<? super T> keyExtractor)
comparingInt源码例子:
public static <T> Comparator<T> comparingInt(ToIntFunction<? super T> keyExtractor) {Objects.requireNonNull(keyExtractor);return (Comparator<T> & Serializable)(c1, c2) -> Integer.compare(keyExtractor.applyAsInt(c1), keyExtractor.applyAsInt(c2));}
3.5.3 NullComparator类
上面所有的方法,都不能对 null 进行比较。例如:下面有个地址=null,那么程序会报错。
List<Emp> empList=new ArrayList();empList.add(new Emp("海淀","小王",20,5000.0));empList.add(new Emp("海淀","小李",50,15000.0));empList.add(new Emp("海淀","小张",30,2000.0));empList.add(new Emp("海淀","小赵",40,20000.0));empList.add(new Emp("海淀","小陈",60,5500.0));empList.add(new Emp(null,"小刘",60,5500.0));empList.stream().sorted(Comparator.comparing(Emp::getAddress).reversed()).forEach(emp->System.out.println(emp));
所以针对 null,只有两种排序方式,放在最前或者最后。所以 Java 引入了NullComparator类
看下面的例子:
System.out.println("按照地址降序,若有空,放到最前面:" );empList.stream().sorted(Comparator.comparing(Emp::getAddress,Comparator.nullsLast(String::compareTo)).reversed()).forEach(emp->System.out.println(emp));
这里用到了Comparator.nullsLast(String::compareTo)
public static <T> Comparator<T> nullsLast(Comparator<? super T> comparator) {return new Comparators.NullComparator<>(false, comparator);}
① 类定义
继承了Comparator,有一个构造函数,需要传入一个比较器与nullFirst
static final class NullComparator<T> implements Comparator<T>, Serializable {private static final long serialVersionUID = -7569533591570686392L;private final boolean nullFirst;// if null, non-null Ts are considered equalprivate final Comparator<T> real;@SuppressWarnings("unchecked")NullComparator(boolean nullFirst, Comparator<? super T> real) {this.nullFirst = nullFirst;this.real = (Comparator<T>) real;}........................................................}
② 重写了 compare
这段代码比较简单,根据nullFirst,来判断是否排在前面或者后面。
@Overridepublic int compare(T a, T b) {if (a == null) {return (b == null) ? 0 : (nullFirst ? -1 : 1);} else if (b == null) {return nullFirst ? 1: -1;} else {return (real == null) ? 0 : real.compare(a, b);}}
③ 重写了 reversed
重写降序,将nullFirst反转,同时将比较器反转。
@Overridepublic Comparator<T> reversed() {return new NullComparator<>(!nullFirst, real == null ? null : real.reversed());}
④ 重写了 thenComparing
thenComparing表示的意思是,如果前面的排序一样,那么选择第二个规则继续排序。
@Overridepublic Comparator<T> thenComparing(Comparator<? super T> other) {Objects.requireNonNull(other);return new NullComparator<>(nullFirst, real == null ? other : real.thenComparing(other));}
3.5.4 thenComparing
① 按原始内容比较
将工资传入进行比价,但是这种只能进行正序排序,如果要进行降序或者非 Null 比较,那么就不能用这个方法了。
empList.stream().sorted(Comparator.comparing(Emp::getAge).reversed().thenComparing(Emp::getSalary)).forEach(emp->System.out.println(emp));
② 传入比较器
创建一个比较器,然后传入。这里就建了一个比较器Comparator.comparing(Emp::getSalary).reversed()
System.out.println("按照年龄降序,如果年龄相同,再按照收入降序排序");empList.stream().sorted(Comparator.comparing(Emp::getAge).reversed().thenComparing(Comparator.comparing(Emp::getSalary).reversed())).forEach(emp->System.out.println(emp));
源码分析
default Comparator<T> thenComparing(Comparator<? super T> other) {Objects.requireNonNull(other);return (Comparator<T> & Serializable) (c1, c2) -> {int res = compare(c1, c2);return (res != 0) ? res : other.compare(c1, c2);};}
③ 传入取值方法与比较器
这种最灵活
认为自身的比较器不好用的时候,可以把第二个参数,作为比较器传入,具体看下面的例子。
System.out.println("按照年龄降序,如果年龄相同,再按照地址降序排序,并且使用自定义的排序方法");empList.stream().sorted(Comparator.comparing(Emp::getAge).reversed().thenComparing(Emp::getAddress,Comparator.nullsFirst(String::compareTo))).forEach(emp->System.out.println(emp));
这里使用了第二个方法
.thenComparing(Emp::getAddress,Comparator.nullsFirst(String::compareTo))
源码分析如下:
default <U> Comparator<T> thenComparing(Function<? super T, ? extends U> keyExtractor,Comparator<? super U> keyComparator){return thenComparing(comparing(keyExtractor, keyComparator));}
④ 其他特定比较方法
将要比较的内容,转换成基础类型,并且利用基础类型进行比较。
thenComparingIntthenComparingLongthenComparingDouble
但是这个类有很多静态方法。
静态方法
| 名称 | 说明 |
|---|---|
| comparing | |
public static <T, U> Comparator<T> comparing(Function<? super T, ? extends U> keyExtractor,Comparator<? super U> keyComparator){Objects.requireNonNull(keyExtractor);Objects.requireNonNull(keyComparator);return (Comparator<T> & Serializable)(c1, c2) -> keyComparator.compare(keyExtractor.apply(c1),keyExtractor.apply(c2));}
3.5.5 reversed
实际上是返回了一个比较类
default Comparator<T> reversed() {return Collections.reverseOrder(this);}
3.5.6 naturalOrder、reverseOrder
public static <T extends Comparable<? super T>> Comparator<T> reverseOrder() {return Collections.reverseOrder();}public static <T extends Comparable<? super T>> Comparator<T> naturalOrder() {return (Comparator<T>) Comparators.NaturalOrderComparator.INSTANCE;}
可以读一下这个类Comparators,里面定义了 Java 的一些比较器。或者可以看一下Comarator的实现类。
3.5.7 源码分析补充

3.6 终端操作
3.6.1 forEach 与 forEachOrder
forEachOrder 主要用在并行的线程处理。
List<String> list = Arrays.asList("a","b","c");System.out.println("正常流输出");list.stream().forEach(System.out::println);System.out.println("并行流输出,使用forEach,顺序会乱");list.parallelStream().forEach(System.out::println);System.out.println("并行流输出,使用forEachOrdered,顺序不乱");list.parallelStream().forEachOrdered(System.out::println);
这两个函数的定义如下:
void forEach(Consumer<? super T> action);void forEachOrdered(Consumer<? super T> action);
3.6.2 toArray
如果不定义数组类型,那么只能输出一个 Object,大部分时候使用 toArray(T[]::new)来表示
List<String> strs = Arrays.asList("a", "b", "c");String[] dd = strs.stream().toArray(size -> new String[size]);String[] dd1 = strs.stream().toArray(String[]::new);Object[] obj = strs.stream().toArray();
String[]::new 意味着 size -> new String[size].
3.6.3 得到某个元素
min,max,findFirst,findAny四个操作,看他们的定义
Optional<T> min(Comparator<? super T> comparator);Optional<T> max(Comparator<? super T> comparator);Optional<T> findFirst();Optional<T> findAny();
下面是具体的例子
List<String> strs = Arrays.asList("d", "b", "a", "c", "a");//自己定义比较的方法Optional<String> min = strs.stream().min((a,b)->a.compareTo(b));Optional<String> max = strs.stream().min((a,b)->b.compareTo(a));System.out.println(String.format("min:%s; max:%s", min.get(), max.get()));//这里演示了Function.identity的用法,实际上不容易理解。Optional<String> min1 = strs.stream().min(Comparator.comparing(Function.identity()));System.out.println(String.format("min:%s; ", min1.get()));Optional<String> first = strs.stream().findFirst();Optional<String> any= strs.stream().findAny();System.out.println(String.format("findAny永远是第一个元素:first:%s; any:%s", first.get(), any.get()));Optional<String> any2= strs.parallelStream().findAny();System.out.println(String.format("parallelStream后,findAny就不一定是第一个元素了:first:%s; any:%s", first.get(), any2.get()));
3.6.4 求和与匹配
count,anyMatch,allMatch,noneMatch
long count();boolean anyMatch(Predicate<? super T> predicate);boolean allMatch(Predicate<? super T> predicate);boolean noneMatch(Predicate<? super T> predicate);
- anyMatch
- 任意一个元素成功,返回 true
- allMatch
- 判断条件里的元素,所有的都是,返回 true
- noneMatch
- 跟 allMatch 相反,判断条件里的元素,所有的都不是,返回 true
- 也可以理解为 notIn
下面是例子:
List<String> strs = Arrays.asList("a", "a", "a", "a", "b");boolean anyMatch= strs.stream().anyMatch(s -> s.equals("b"));boolean allMatch= strs.stream().allMatch(s -> s.equals("b"));boolean noneMatch= strs.stream().noneMatch(s -> s.equals("e"));long count = strs.stream().filter(s -> s.equals("b")).count();System.out.println(anyMatch);// trueSystem.out.println(allMatch);// falseSystem.out.println(noneMatch);// trueSystem.out.println(count);
3.6.5 reduce
① 函数定义
一个有三个可用的函数
T reduce(T identity, BinaryOperator<T> cc);Optional<T> reduce(BinaryOperator<T> accumulator);<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
identity
- 是初始值,如果没有,就等于 0
accumulator
- 累加器函数
- 有两个参数,第一个参数是累加的结果,第二个是 stream 中的下一个值。
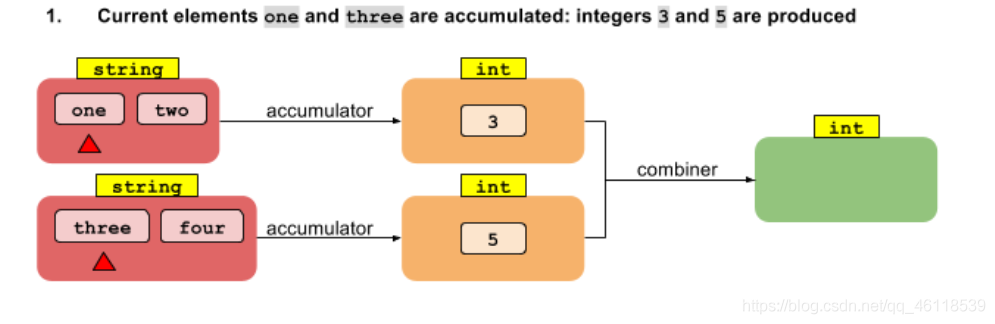
combiner
- 合成器函数,这个仅仅在
parallelStream,并行流中有作用 - 如果没有指定,那么与 accumulator 相同。
- 下图是关于 combiner 的一个说明
- 合成器函数,这个仅仅在
可以看看 Java 的 注释写的挺好的。reduce 大概是下面的功能。
* boolean foundAny = false;* T result = null;* for (T element : this stream) {* if (!foundAny) {* foundAny = true;* result = element;* }* else* result = accumulator.apply(result, element);* }* return foundAny ? Optional.of(result) : Optional.empty();
② 简单的例子
通过执行这个例子,可以通过 Debug,进入到源代码,看看程序是怎么执行的。
@Testpublic void testReduce(){Integer[] iArray= {1,2,3,4,5};// 形式1: 默认初始值=0var ren= Arrays.stream(iArray).reduce((a,b)->a+b);System.out.println(ren.get());// 形式2: 默认初始值=10var ren2=Arrays.stream(iArray).reduce(10,(a,b)->a+b);System.out.println(ren2);// 形式3: 默认初始值=0, 这里指定了combiner=【(a,b)->a+b+1】,但是在同步stream下没有用,程序不会执行到var ren3=Arrays.stream(iArray).reduce(0,(a,b)->a+b,(a,b)->a+b+1);System.out.println(ren3);// 形式3: 默认初始值=0,并行stream, 没有指定combiner,默认是`(a,b)->a+b`var ren5=Arrays.asList(iArray).parallelStream().reduce(0,(a,b)->a+b);System.out.println(ren5);var ren6=Arrays.asList(iArray).parallelStream().reduce(0,(a,b)->a+b,(a,b)->a+b+2);System.out.println(ren6);}
③ 统计字母例子
输入{"a","b","a","c","a"}, 输出{a=3, b=1, c=1}
@Testpublic void testReduce3(){String[] words={"a","b","a","c","a"};var end= Arrays.asList(words).stream().map(w->(Map)new HashMap<String,Integer>(){{ put(w,1);}}).reduce(StreamTest::mergeHashMap);System.out.println(end.get());}@Testpublic void testReduce4(){String[] words={"a","b","a","c","a"};var end= Arrays.asList(words).parallelStream().map(w->(Map)new HashMap<String,Integer>(){{ put(w,1);}}).reduce(StreamTest::mergeHashMap);System.out.println(end.get());}public static Map<String,Integer> mergeHashMap(Map<String,Integer> bashHash,Map<String,Integer> nextMap){nextMap.forEach((k,v)->{if(bashHash.get(k)==null){bashHash.put(k,v);}else{bashHash.put(k,v+bashHash.get(k));}});return bashHash;}
这样写,纯粹为了减少代码量,可能看起有点陌生,所以解释一下。
w->(Map)new HashMap<String,Integer>(){{ put(w,1);}}- 返回一个 Map
new HashMap<String,Integer>(){{ put(w,1);}}两个花括号,直接复值
reduce(StreamTest::mergeHashMap)- 等价于:
reduce((a,b)->StreamTest.mergeHashMap(a,b))
- 等价于:
3.6.6 collet
① 函数定义
<R> R collect(Supplier<R> supplier,BiConsumer<R, ? super T> accumulator,BiConsumer<R, R> combiner);<R, A> R collect(Collector<? super T, A, R> collector);
常用的算法,都集中在第二函数定义中,并且Collector中定义了大部分可能需要情况。有兴趣可以看看 Java 源代码,看 Java 是怎么来计算的。


② 转 List、Map、Set
| 名称 | 参数 | 说明 |
|---|---|---|
| toMap | Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper | key value |
| toMap | Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper, BinaryOperator mergeFunction | 多了一个合并规则 |
| toMap | Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper, BinaryOperator mergeFunction, Supplier | 多了初始值 |
| toConcurrentMap | 与 toMap 一样,有三种形式 | |
| toCollection | Supplier | |
| toList | ||
| toSet | ||
| toUnmodifiableList | 返回一个不可以修改的 | |
| toUnmodifiableMap | 返回一个不可以修改的 | |
| toUnmodifiableSet | 返回一个不可以修改的 |
这里假设有一个empList
List<Emp> getEmpList(){List<Emp> empList=new ArrayList();empList.add(new Emp("海淀","小王",20,5000.0));empList.add(new Emp("海淀","小李",50,15000.0));empList.add(new Emp("海淀","小张",30,2000.0));empList.add(new Emp("朝阳","小赵",40,20000.0));empList.add(new Emp("朝阳","小陈",60,5500.0));empList.add(new Emp(null,"小刘",60,5500.0));return empList;}List<Emp> empList = getEmpList();
// 转listList<String> names=empList.stream().map(e->e.getName()).collect(Collectors.toList());System.out.println(names);// 转setSet<String> names2= empList.stream().map(e->e.getName()).collect(Collectors.toSet());System.out.println(names2);// // 转map,需要指定key和value,Function.identity()表示当前的Emp对象本身// 这里有一个非常的知识点:Function.identity()var map= empList.stream().collect(Collectors.toMap(Emp::getName,Function.identity()));System.out.println(map);
上述是常见的用法,如果读取源代码,会发现有很多函数可以用。例如:
public static <T, K, U>Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,Function<? super T, ? extends U> valueMapper,BinaryOperator<U> mergeFunction) {return toMap(keyMapper, valueMapper, mergeFunction, HashMap::new);}
那么重新看一下单词统计,就可以很简单的撰写出来了
@Testpublic void testReduce11(){String[] words={"a","b","a","c","a"};Map<String,Integer> end= Arrays.asList(words).stream().collect(Collectors.toMap(Function.identity(),w->1,(result,next)->result+next));System.out.println(end);}
③ 求和、最小、最大、平均
给出一些例子
// 计算元素中的个数var count=empList.stream().count();var count1=empList.stream().collect(Collectors.counting());System.out.println("count:" +count+" count1:"+count1);//数据求和 summingInt summingLong,summingDoublevar ageSum=empList.stream().collect(Collectors.summingInt(Emp::getAge));System.out.println(ageSum);// 平均值 averagingInt,averagingDouble,averagingLongvar averAge=empList.stream().collect(Collectors.averagingInt(Emp::getAge));System.out.println(averAge);// 综合处理的,求最大值,最小值,平均值,求和操作// summarizingInt,summarizingLong,summarizingDouble// IntSummaryStatistics{count=6, sum=260, min=20, average=43.333333, max=60}var summarizingAge=empList.stream().collect(Collectors.summarizingInt(Emp::getAge));System.out.println(summarizingAge);
下面列举一些函数
| 名称 | 参数 | 说明 |
|---|---|---|
| counting() | 无 | 调用了 summingLong |
| summingLong | ToLongFunction<? super T> mapper | 参数是得到数值的方法 |
| summingInt | ToIntFunction<? super T> mapper | 参数是得到数值的方法 |
| summingDouble | ToDoubleFunction<? super T> mapper | 参数是得到数值的方法 |
| summarizingLong | ToLongFunction<? super T> mapper | 得到综合处理结果 |
| summarizingInt | ToIntFunction<? super T> mapper | 得到综合处理结果 |
| summarizingDouble | ToDoubleFunction<? super T> mapper | 得到综合处理结果 |
| averagingDouble | ToDoubleFunction<? super T> mapper | 求平均值 |
| averagingInt | ToIntFunction<? super T> mapper | 求平均值 |
| averagingLong | ToLongFunction<? super T> mapper | 求平均值 |
| maxBy | Comparator<? super T> comparator | 自定义比较方法 |
| minBy | Comparator<? super T> comparator | 自定义比较方法 |
maxBy自定义比较方法的例子:这里取出年龄最大的对象
var maxAge3 = empList.stream().collect(Collectors.maxBy(Comparator.comparing(e->e.getAge())));
④ 字符串拼接
看例子
// 连接字符串,当然也可以使用重载的方法,加上一些前缀,后缀和中间分隔符String strName=empList.stream().map(e->e.getName()).collect(Collectors.joining());System.out.println(strName);String strName1=empList.stream().map(e->e.getName()).collect(Collectors.joining("-中间的分隔符-"));System.out.println(strName1);String strName2=empList.stream().map(e->e.getName()).collect(Collectors.joining("-中间的分隔符-", "前缀*", "&后缀"));System.out.println(strName2);
使用起来比较简单,这里就不列举了函数定义的内容了。
⑤ reduce 操作
先看例子
// 归约操作var reducing=empList.stream().map(e->e.getAge()).collect(Collectors.reducing((x,y)->x+1+y));System.out.println(reducing);var reducing2=empList.stream().map(e->e.getAge()).collect(Collectors.reducing(1000,(x,y)->x+1+y));System.out.println(reducing2);var reducing3=empList.stream().collect(Collectors.reducing(1000,e->e.getAge(),(x,y)->x+1+y));System.out.println(reducing3);
有三个定义
| 名称 | 参数 | 说明 |
|---|---|---|
| reducing | BinaryOperator | 累加的方法 |
| reducing | T identity, BinaryOperator | 多了一个初始值 |
| reducing | U identity, Function<? super T, ? extends U> mapper, BinaryOperator op | 多了一个过滤的函数 |
⑥ group 操作
// 分操作 groupingBy 根据地址,把原list进行分组Map<String, List<Emp>> group = empList.stream().collect(Collectors.groupingBy(e->e.getAddress()==null?"空地址":e.getAddress()));System.out.println(group);// partitioningBy 分区操作 需要根据类型指定判断分区Map<Boolean, List<Emp>> pgroup=empList.stream().collect(Collectors.partitioningBy(e->e.getAge()>30));System.out.println(pgroup);
group 有很多的定义
| 名称 | 参数 | 说明 |
|---|---|---|
| groupingBy | Function<? super T, ? extends K> classifier | 传入一个分配器 看例子,就是返回一个名称 这个函数会调用下面的函数,默认返回一个 List |
| groupingBy | Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream | 多了一个参数:downstream,下游 stream |
| groupingBy | Function<? super T, ? extends K> classifier, Supplier Collector<? super T, A, D> downstream | Supplier,可以被上一个函数调用,默认是:HashMap::new |
| groupingByConcurrent | Function<? super T, ? extends K> classifier | 默认是 ConcurrentHashMap::new |
| groupingByConcurrent | Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream | 默认是 ConcurrentHashMap::new |
| groupingByConcurrent | Function<? super T, ? extends K> classifier, Supplier Collector<? super T, A, D> downstream | 默认是 ConcurrentHashMap::new |
| partitioningBy | Predicate<? super T> predicate | |
| partitioningBy | Predicate<? super T> predicate, Collector<? super T, A, D> downstream |
为什么 Group 有那么多参数呢? 因为可以定制Collector,在 Collector 中实现下面个性化定义。
- supplier 初始值
- accumulator 求和
- combiner 组合
- finisher 最后
⑦ filtering
晕掉了,在 Collector 中还有 fiter 与 flatMap。 Java 的注释写的还是很清楚的。
[filtering]与[filter]的区别是,就算是没有,[filtering]也可以输出。,常常用在 groupby 中。
Map<String, List<Emp>> group= getEmpList().stream().collect(Collectors.groupingBy(e->e.getAddress()==null?"空地址":e.getAddress()));System.out.println(group);//{海淀=[], 朝阳=[Emp(address=朝阳, name=小陈, age=60, salary=5500.0)], 空地址=[Emp(address=null, name=小刘, age=60, salary=5500.0)]}Map<String, List<Emp>> group1= getEmpList().stream().collect(Collectors.groupingBy(e->e.getAddress()==null?"空地址":e.getAddress(),Collectors.filtering(e->e.getAge()>50,Collectors.toList())));System.out.println(group1);// {朝阳=[Emp(address=朝阳, name=小陈, age=60, salary=5500.0)], 空地址=[Emp(address=null, name=小刘, age=60, salary=5500.0)]}Map<String, List<Emp>> group2= getEmpList().stream().filter(e->e.getAge()>50).collect(Collectors.groupingBy(e->e.getAddress()==null?"空地址":e.getAddress()));System.out.println(group2);
⑧ flatMapping
看看这个函数的定义。
- mapper:一个函数,用来返回一个 stream 结果,表示被输入的元素。
- downstream:下游收集器,会接受从
mapper中的元素。 - 这个函数返回一个收集器,通过 mapping 函数接受输入元素并提供一个 flatMap 结果给下游收集器。
public static <T, U, A, R>Collector<T, ?, R> flatMapping(Function<? super T, ? extends Stream<? extends U>> mapper,Collector<? super U, A, R> downstream)
在下面的例子中 Collector.flatMapping 与 Stream.flatMap 没有区别
String[] words = new String[]{"Hello", "World","you"};//flat实际上,将一个stream转换成两外一个streamStream.of(words).flatMap(s -> Stream.of(s.split(""))).forEach(System.out::println);System.out.println("----------与上面的没有区别-------------------");Stream.of(words).collect(Collectors.flatMapping(l->Stream.of(l.split("")),Collectors.toList())).forEach(System.out::println);
但是Stream.flatMap在 Group 中就有用途了。
String[] words = new String[]{"Hello", "World", "you"};var f=Stream.of(words).collect(Collectors.groupingBy(a->a.length()));System.out.println(f);System.out.println("----------通过嵌套flatMapping-------------------");var f1=Stream.of(words).collect(Collectors.groupingBy(a->a.length(),Collectors.flatMapping(l->Stream.of(l.split("")),Collectors.toList())));System.out.println(f1);
上面的例子会输出,通过Collectors.flatMapping将元素给分解了
{3=[you], 5=[Hello, World]}----------通过嵌套flatMapping-------------------{3=[y, o, u], 5=[H, e, l, l, o, W, o, r, l, d]}
其实 Java 代码注释中的例子就很容易理解,将一个 Orders 进行了扁平化
* <pre>{@code* Map<String, Set<LineItem>> itemsByCustomerName* = orders.stream().collect(* groupingBy(Order::getCustomerName,* flatMapping(order -> order.getLineItems().stream(),* toSet())));* }</pre>
⑨ collectingAndThen
对一个Collector执行一个附加的finishing转换器。
看定义,第一个参数式一个收集器,第二个参数是对收集器中的数据进行处理。
public static<T,A,R,RR> Collector<T,A,RR> collectingAndThen(Collector<T,A,R> downstream,Function<R,RR> finisher) {}
如何优化下面的代码,这里借鉴了flatMapping的例子
String[] words = new String[]{"Hello", "World", "you"};var f1=Stream.of(words).collect(Collectors.groupingBy(a->a.length(),Collectors.flatMapping(l->Stream.of(l.split("")),Collectors.toList())));System.out.println(f1);//{3=[y, o, u], 5=[H, e, l, l, o, W, o, r, l, d]}
现在相对输出的结果进行去重,{3=[y, o, u], 5=[H, e, l, o, W, r, d]}
那么需要对flatMapping的输出结果,进行再一次处理。所以要用到Collectors.colletingAndThen,代码如下:
String[] words = new String[]{"Hello", "World", "you"};var f1=Stream.of(words).collect(Collectors.groupingBy(a->a.length(),Collectors.collectingAndThen(Collectors.flatMapping(l->Stream.of(l.split("")),Collectors.toList()),r->r.stream().distinct().collect(Collectors.toList()))));System.out.println(f1);
4. Optional
4.1 创建
只能通过三个构造函数进行创建
private Optional() {this.value = null;}private Optional(T value) {this.value = Objects.requireNonNull(value);}public static <T> Optional<T> empty() {@SuppressWarnings("unchecked")Optional<T> t = (Optional<T>) EMPTY;return t;}public static <T> Optional<T> of(T value) {return new Optional<>(value);}public static <T> Optional<T> ofNullable(T value) {return value == null ? empty() : of(value);
4.2 获取
public T get() {if (value == null) {throw new NoSuchElementException("No value present");}return value;}public T orElse(T other) {return value != null ? value : other;}public T orElseGet(Supplier<? extends T> other) {return value != null ? value : other.get();}public <X extends Throwable> T orElseThrow(Supplier<? extends X> exceptionSupplier) throws X {if (value != null) {return value;} else {throw exceptionSupplier.get();}}
可以看到,有 4 种取泛型参数的方式;
1.get()直接取,如果为 null,就返回异常
2.orElse(T other)在取这个对象的时候,设置一个默认对象(默认值);如果当前对象为 null 的时候,就返回默认对象
3.orElseGet(Supplier<? extends T> other)跟第二个是一样的,区别只是参数,传入了一个函数式参数;
4.orElseThrow(Supplier<? extends X> exceptionSupplier)第四个,跟上面表达的是一样的,为 null 的时候,返回一个特定的异常;
4.3 辅助方法
public boolean isPresent() {return value != null;}public void ifPresent(Consumer<? super T> consumer) {if (value != null)consumer.accept(value);}public Optional<T> filter(Predicate<? super T> predicate) {Objects.requireNonNull(predicate);if (!isPresent())return this;elsereturn predicate.test(value) ? this : empty();}public <U> Optional<U> map(Function<? super T, ? extends U> mapper) {Objects.requireNonNull(mapper);if (!isPresent())return empty();else {return Optional.ofNullable(mapper.apply(value));}}public <U> Optional<U> flatMap(Function<? super T, Optional<U>> mapper) {Objects.requireNonNull(mapper);if (!isPresent())return empty();else {return Objects.requireNonNull(mapper.apply(value));}}
isPresent()是对当前的 value 进行 null 判断ifPresent(Consumer<? super T> consumer),是要对现有的元素进行处理filter(Predicate<? super T> predicate)对现有函数进行验证map(Function<? super T, ? extends U> mapper)flatMap(Function<? super T, Optional<U>> mapper)类型转换
参考资料
lambda 表达式
函数式接口
stream 接口操作
- 《java8 Stream 接口简介》
- 《 java8 Stream-创建流的几种方式》
- 《JAVA8 stream 接口 中间操作和终端操作》
- 《JAVA8 Stream 接口,map 操作,filter 操作,flatMap 操作》
- 《JAVA8 stream 接口 distinct,sorted,peek,limit,skip》
- 《java8 stream 接口 终端操作 forEachOrdered 和 forEach》
- 《java8 stream 接口 终端操作 toArray 操作》
- 《java8 stream 接口 终端操作 min,max,findFirst,findAny 操作》
- 《java8 stream 接口终端操作 count,anyMatch,allMatch,noneMatch》
- 《java8 srteam 接口终端操作 reduce 操作》
- 《java8 stream 接口 终端操作 collect 操作》
其他部分